Two weeks ago I found myself frustrated – I had been using Emby on my homelab (stand in for plex/kodi/whatever) and started seeing advertisements pop up in my last place of refuge.
So, I thought to myself, hey – this is a well defined domain, I recently got laid off, why not create my own?
Within a day or two I had a functional prototype. Two weeks later I am basically done. There’s definitely some UI/UX stuff I would want to polish for a greater audience, but it works great for me.
Some things that were core in my mind for delivery:
- A page refresh shouldn’t break playback, ever.
- A user’s state is useful to remember not just resume this song, but resume this playlist, and support adding, removing, and replacing the existing playlists fluidly.
- Mixed multi-media playlists.
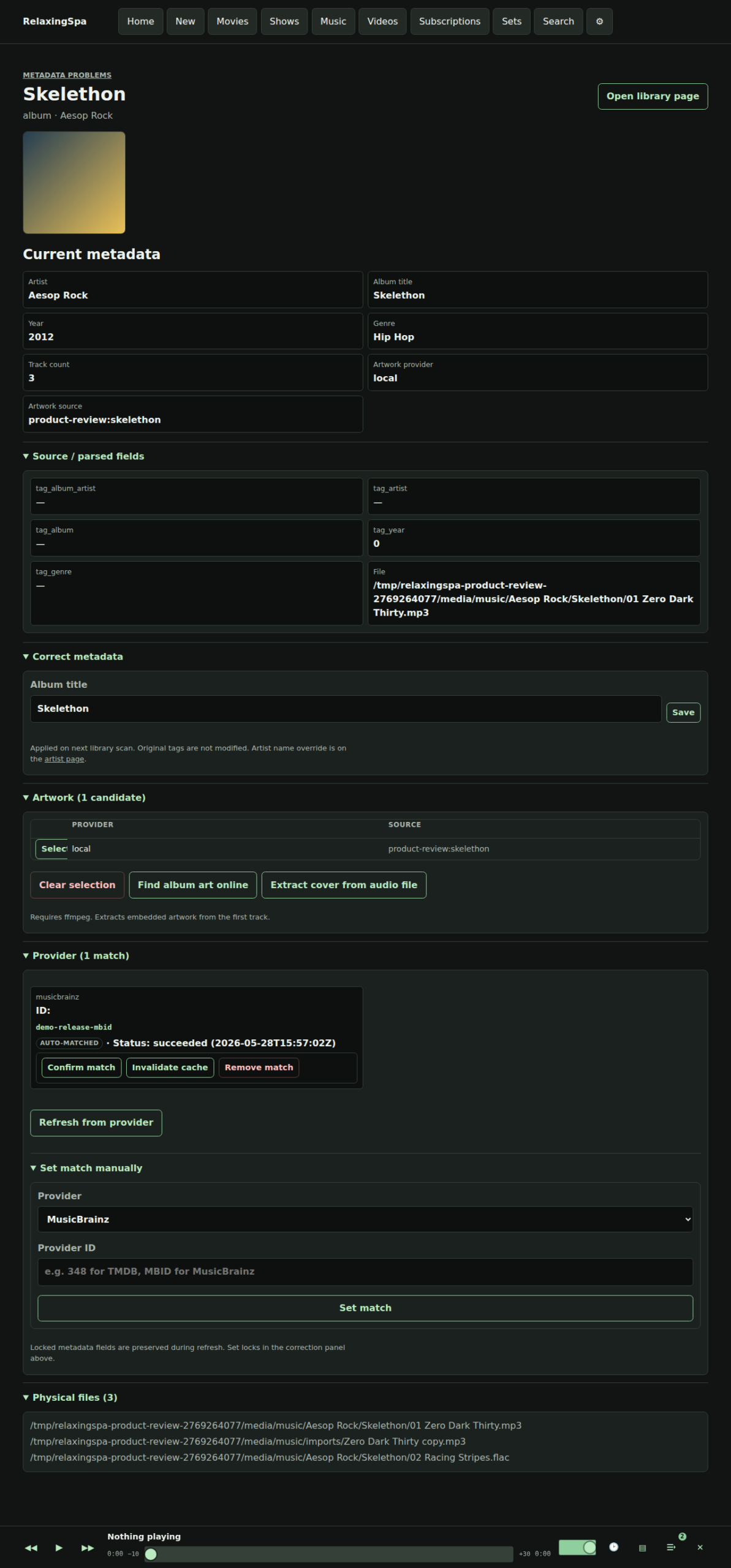
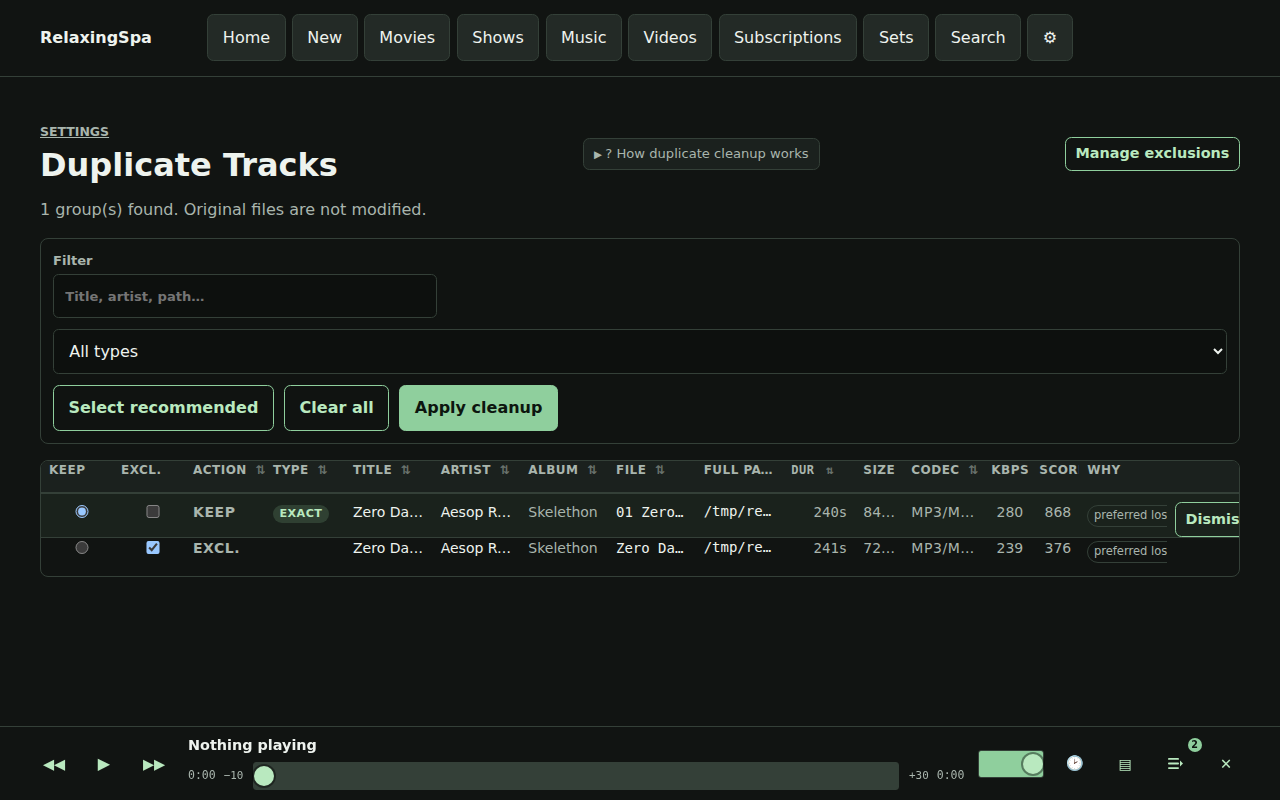
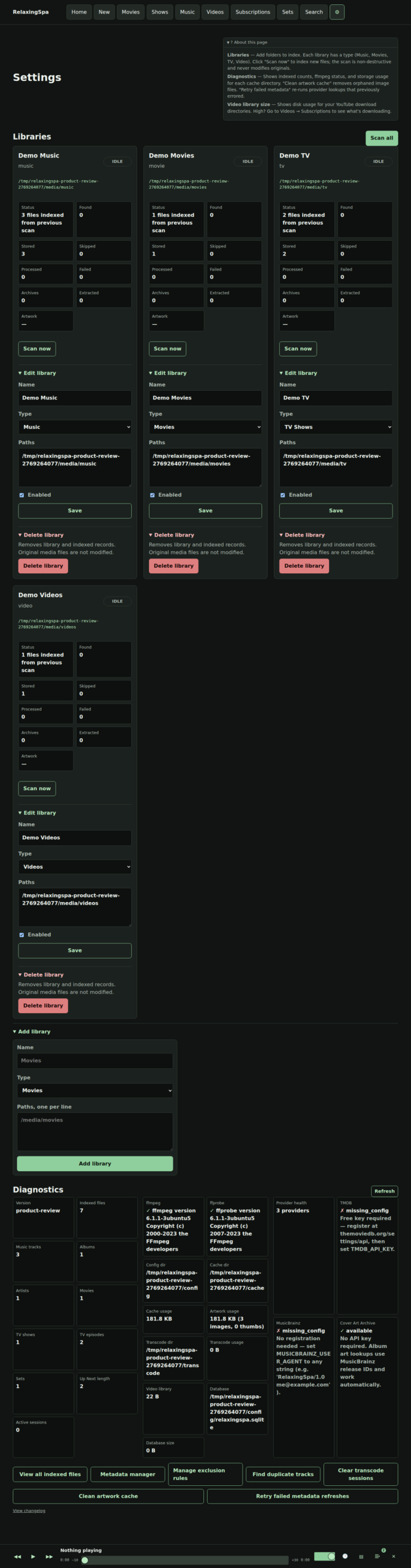
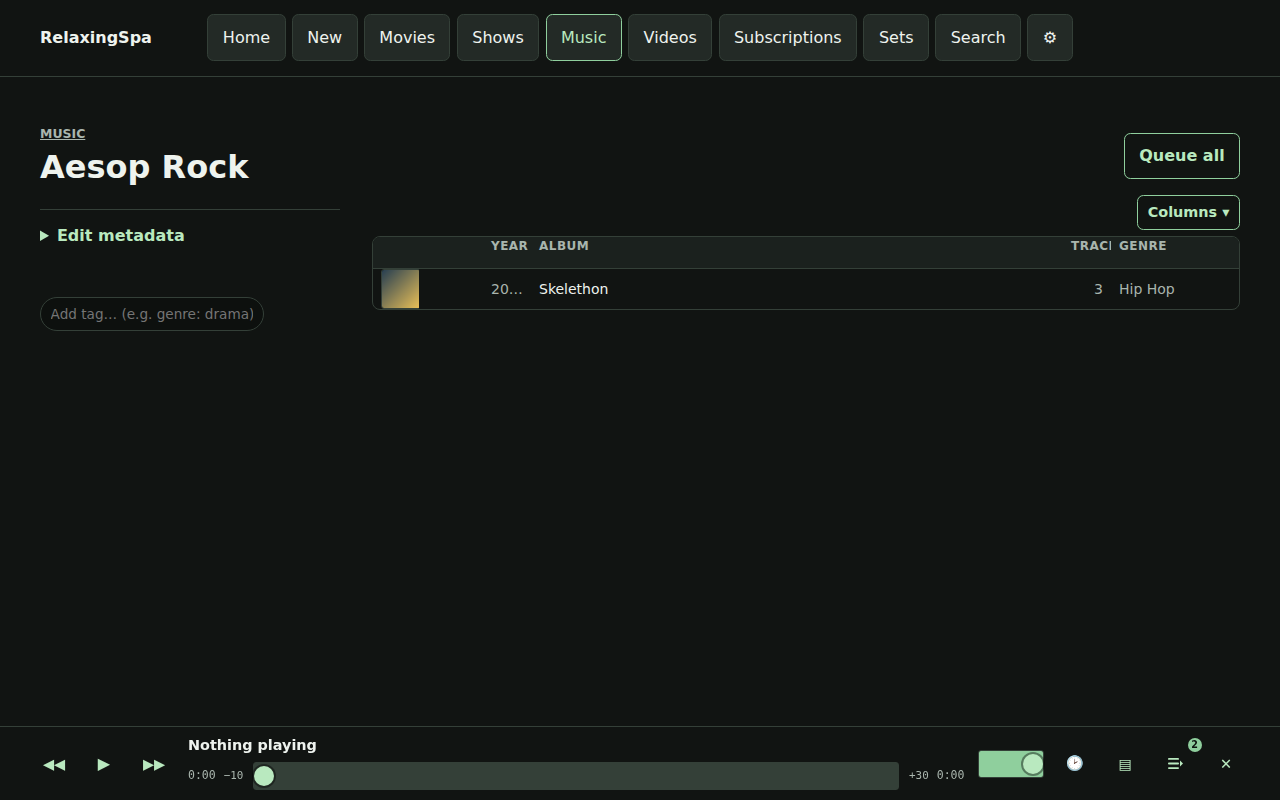
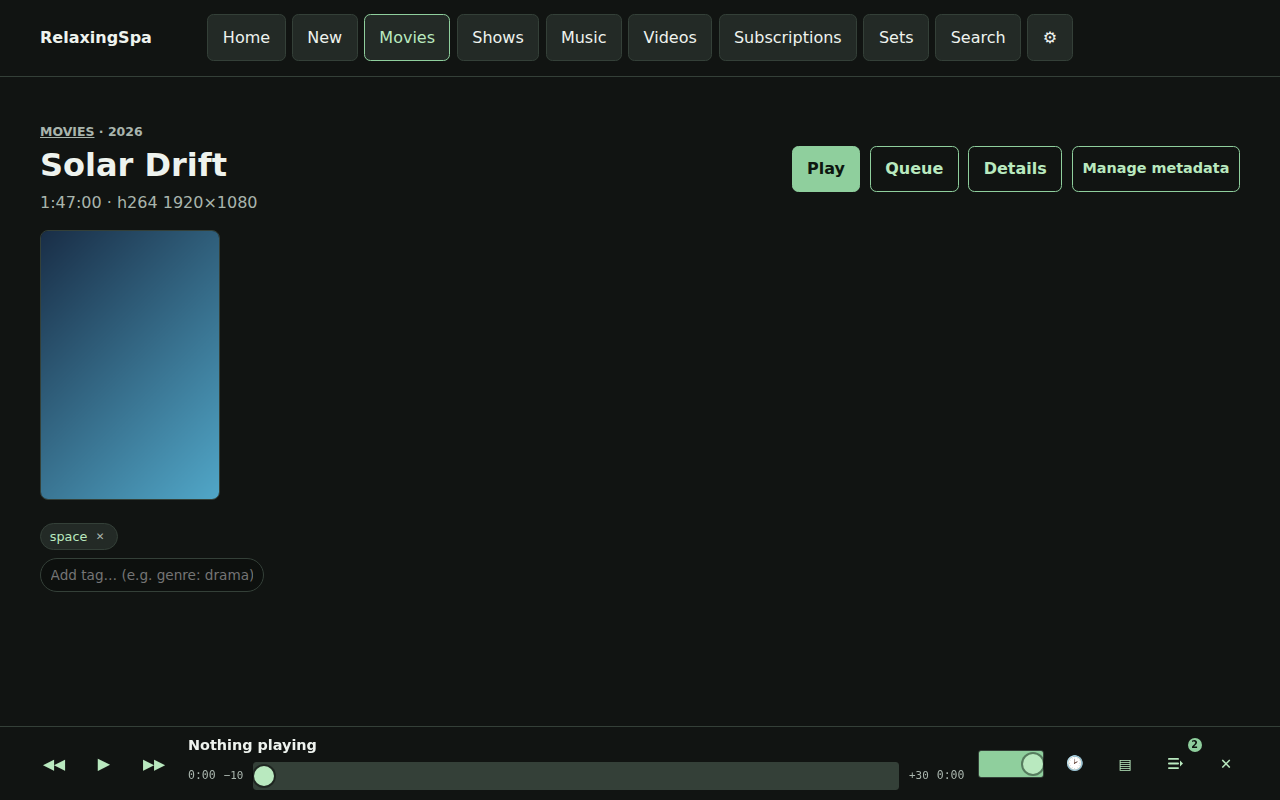
- Duplication removal and managing files needs to be WAY EASIER if you are managing local libraries – I don’t like Spotify.
- It should support iOS and mobile without having to install an app (don’t want to deal with sideloading or an app store fee.)
- It needs to be fast to load and respond – no React, Vite, no third party data stuff, everything local, everything issuing asynchronous calls and replacing the current context while remaining responsive.
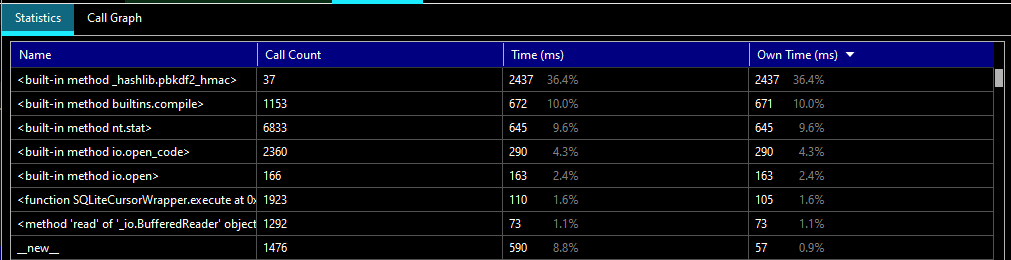
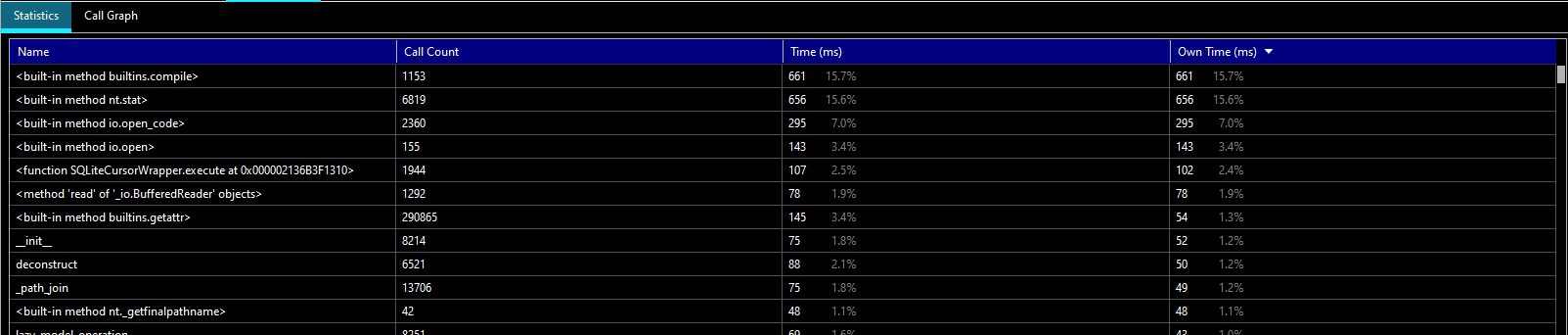
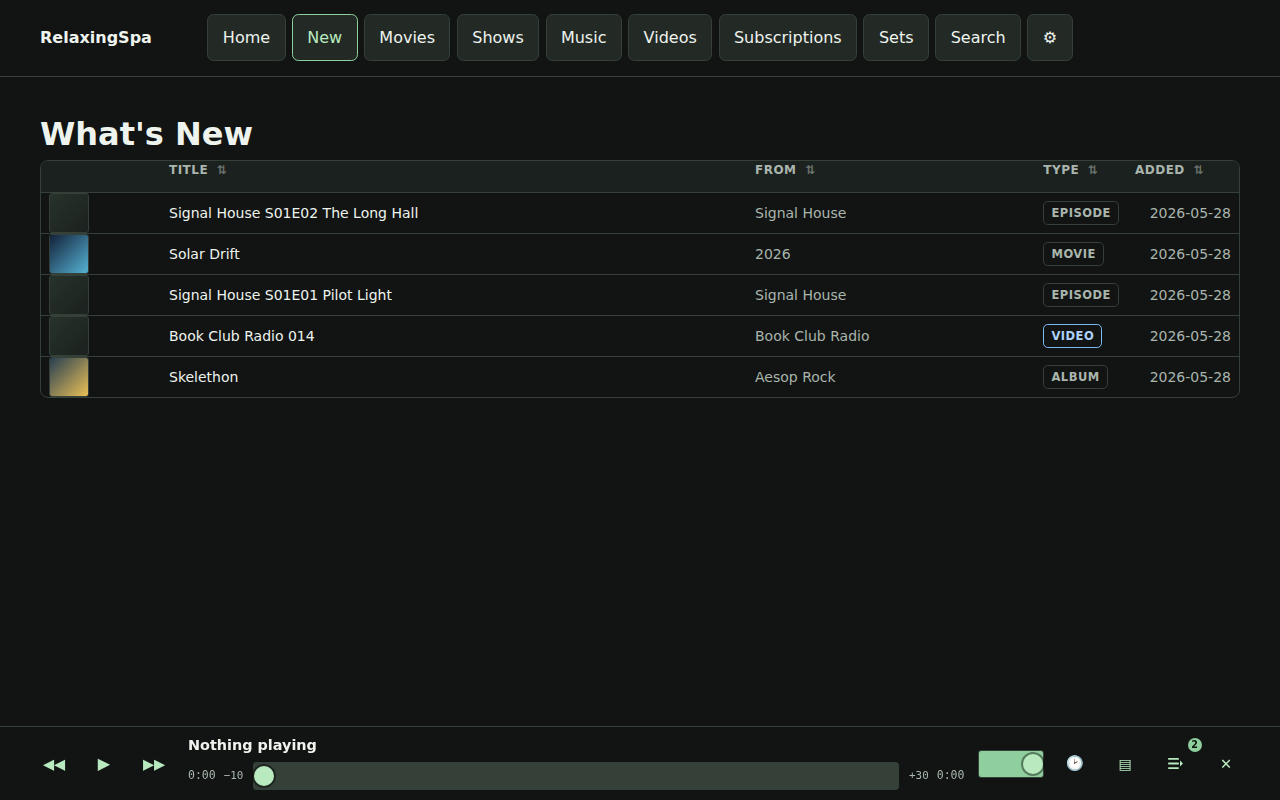
Here’s a little product review that’s produced every time a build completes.

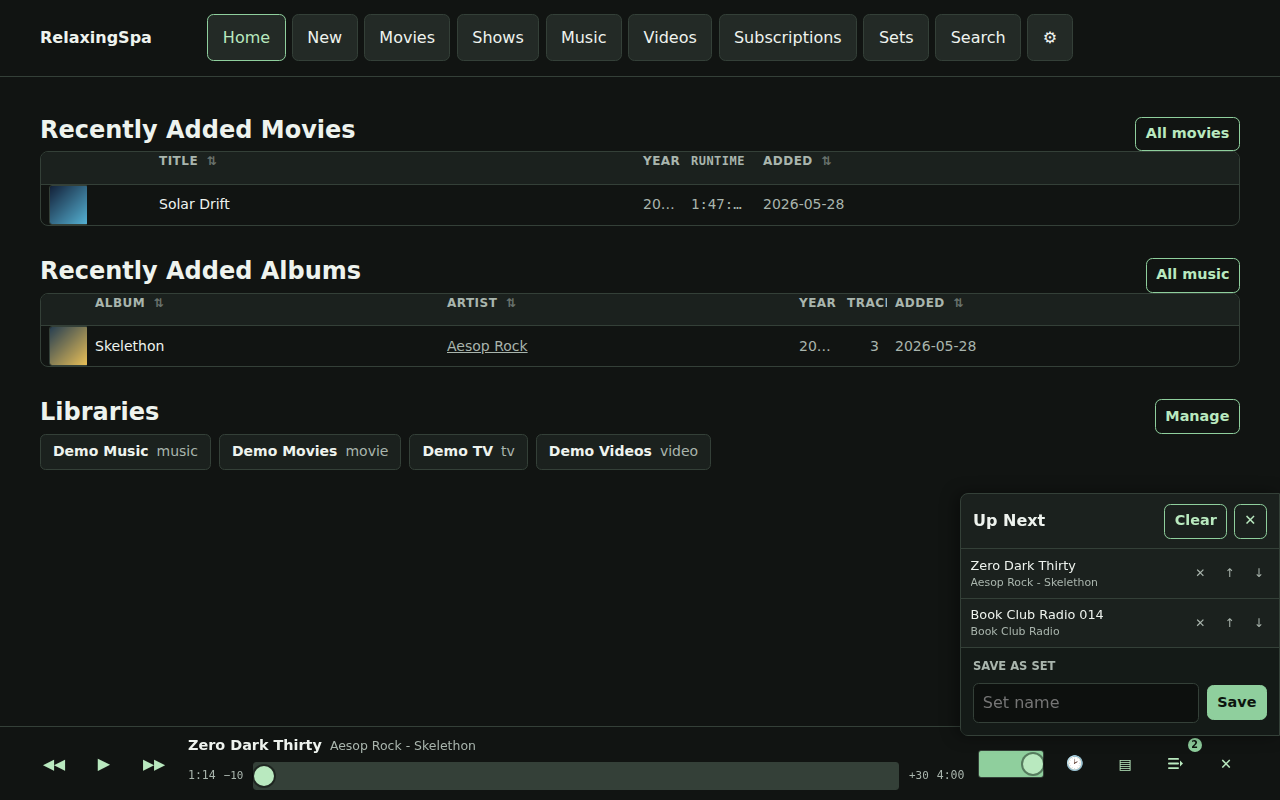
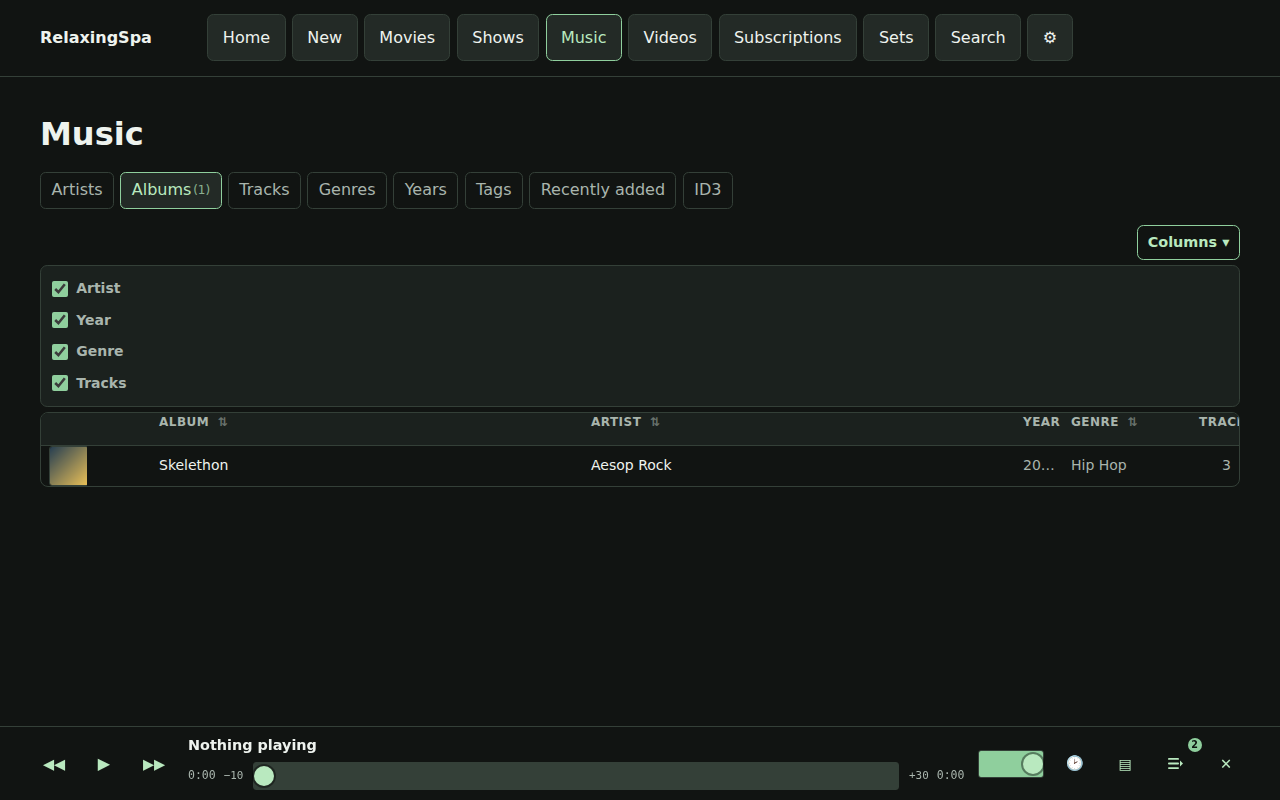
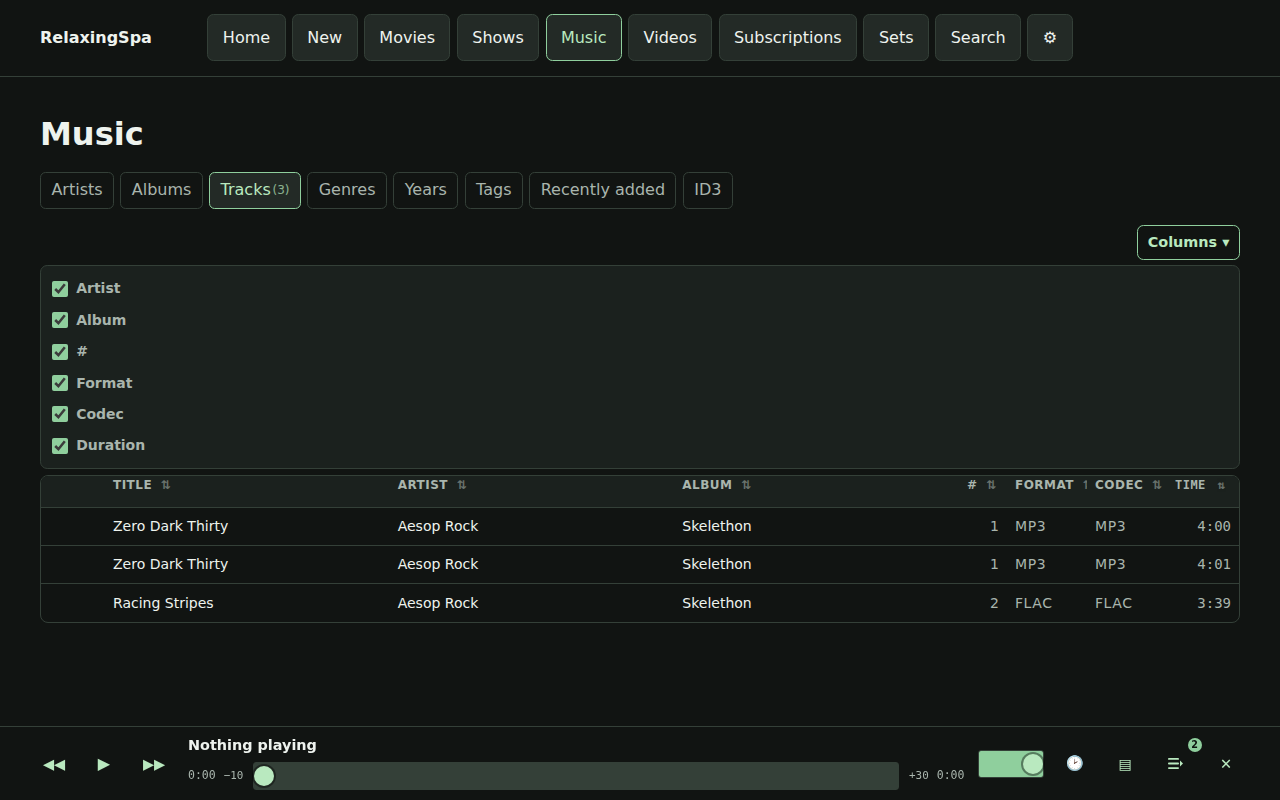
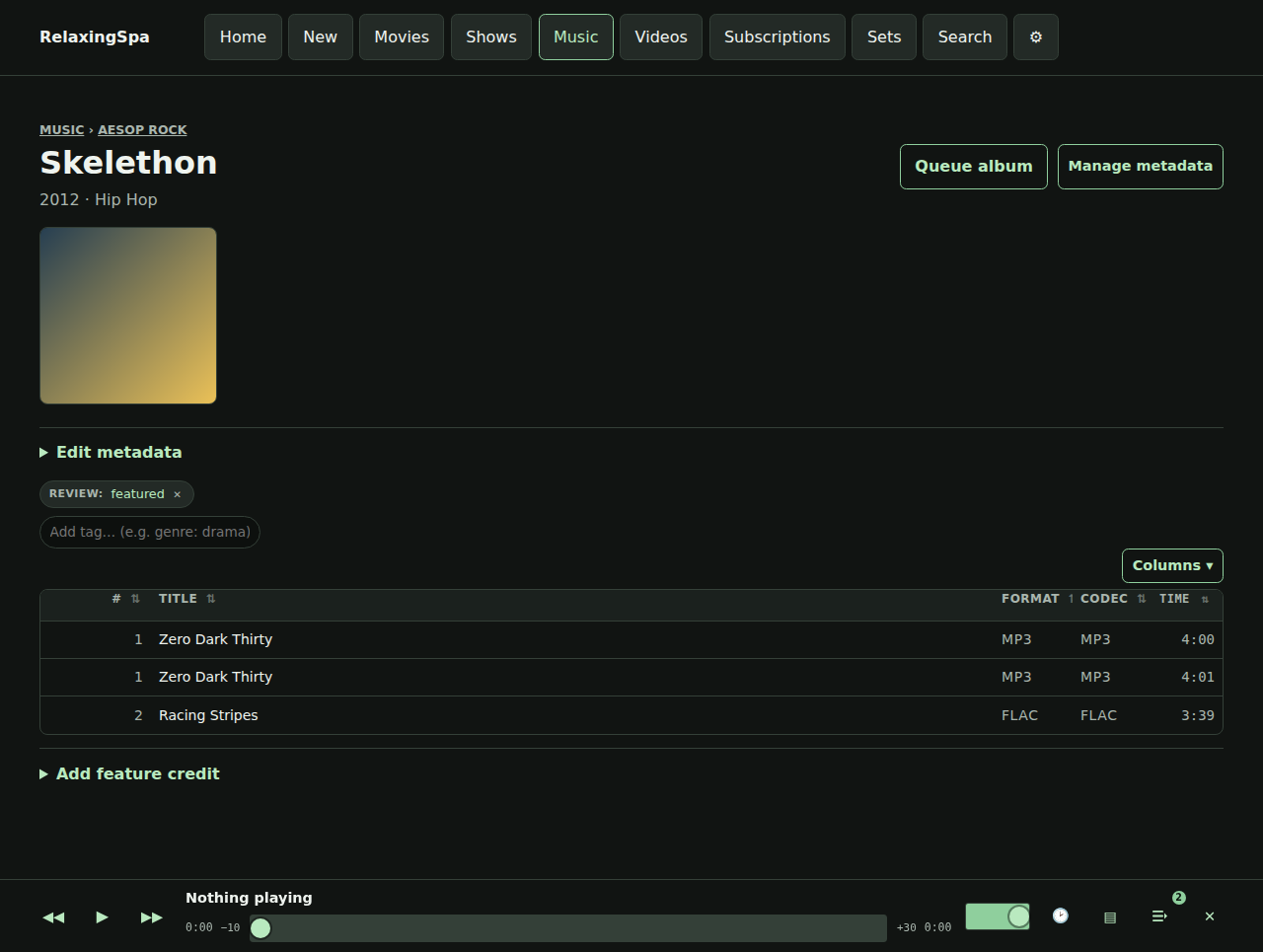
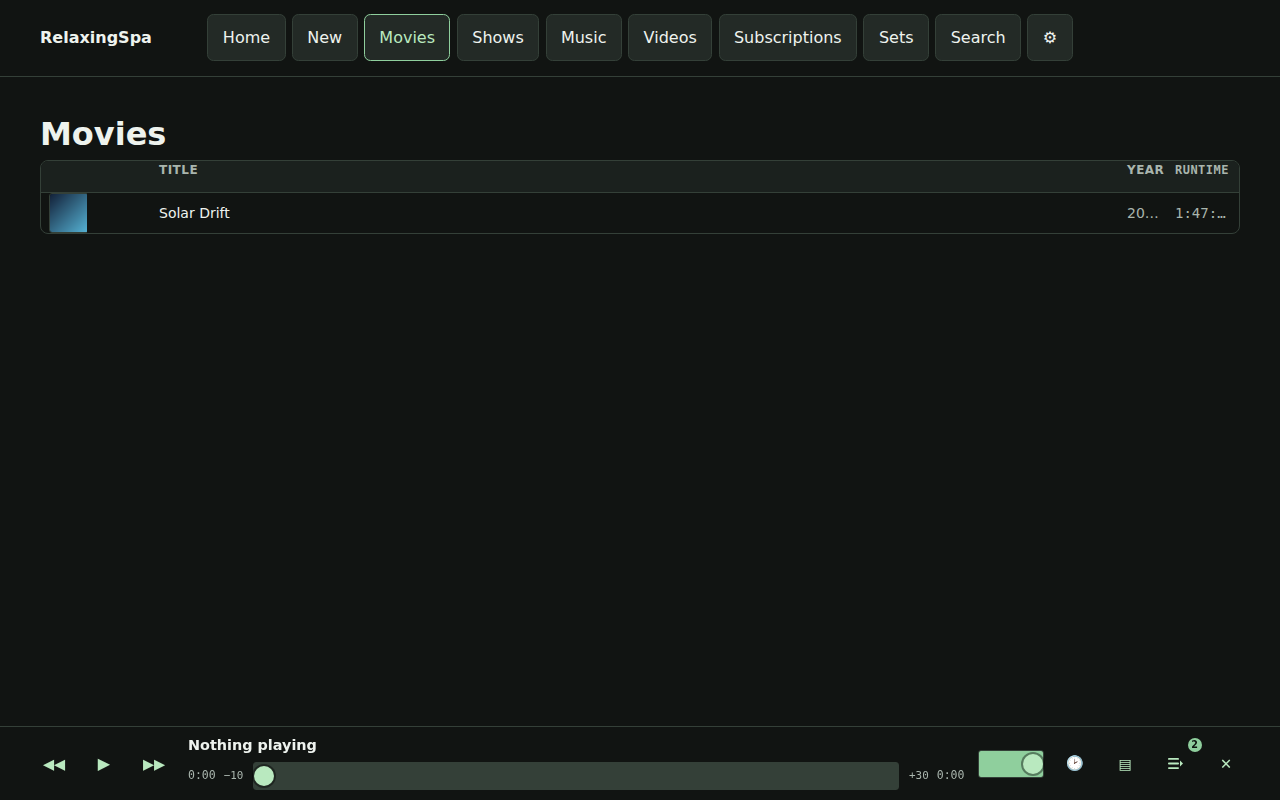
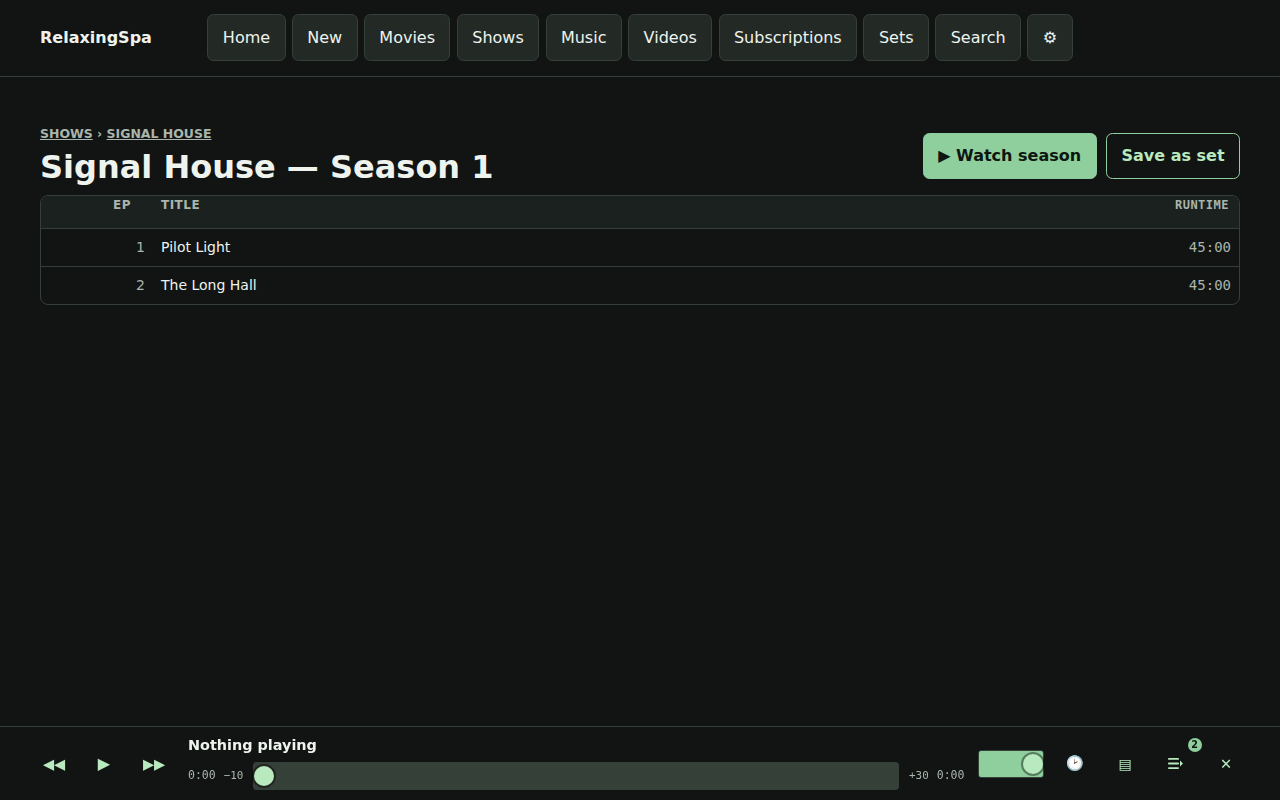
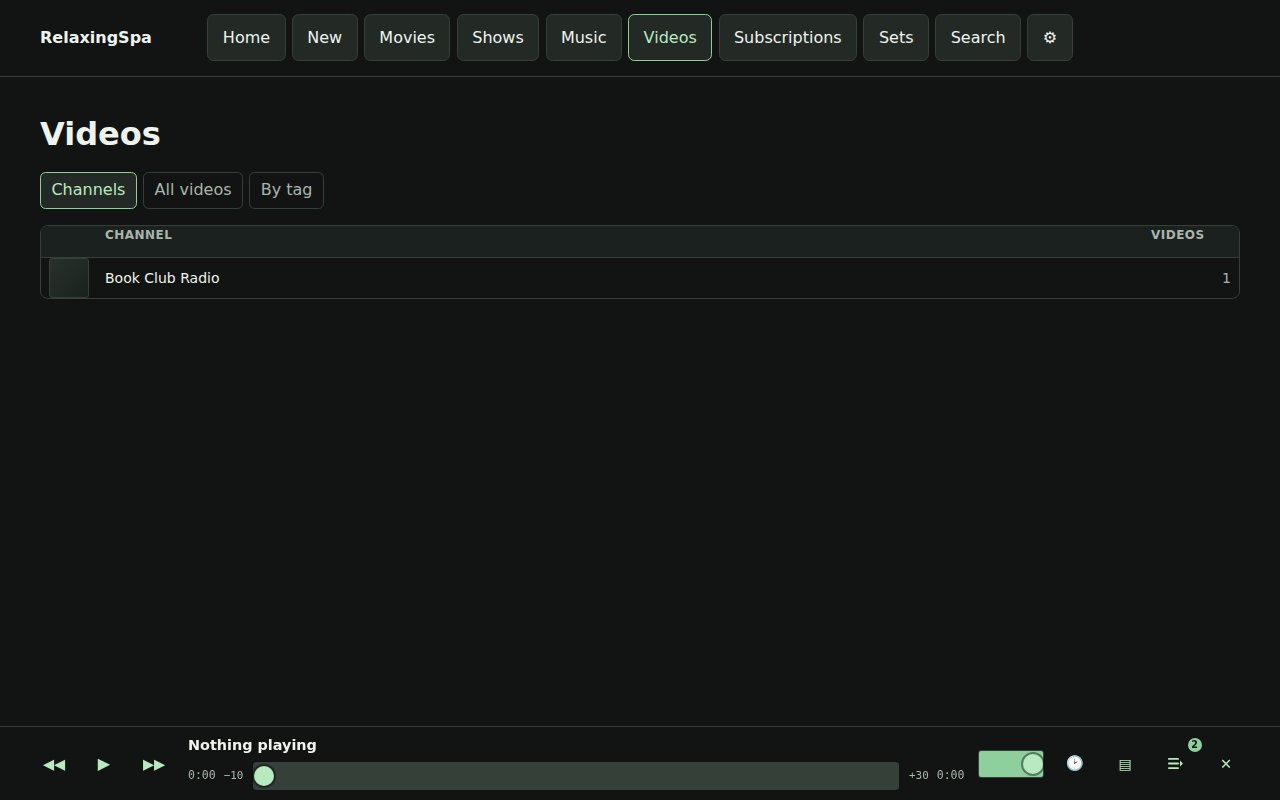
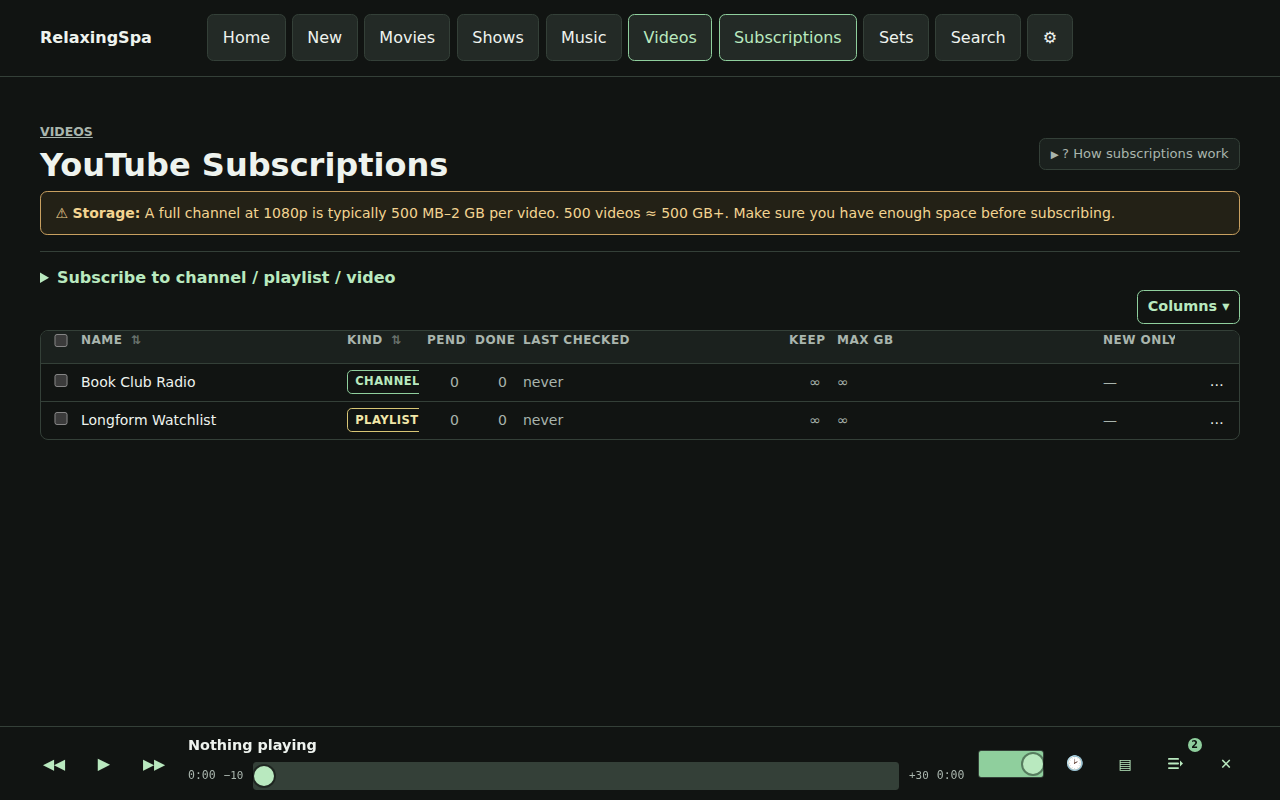

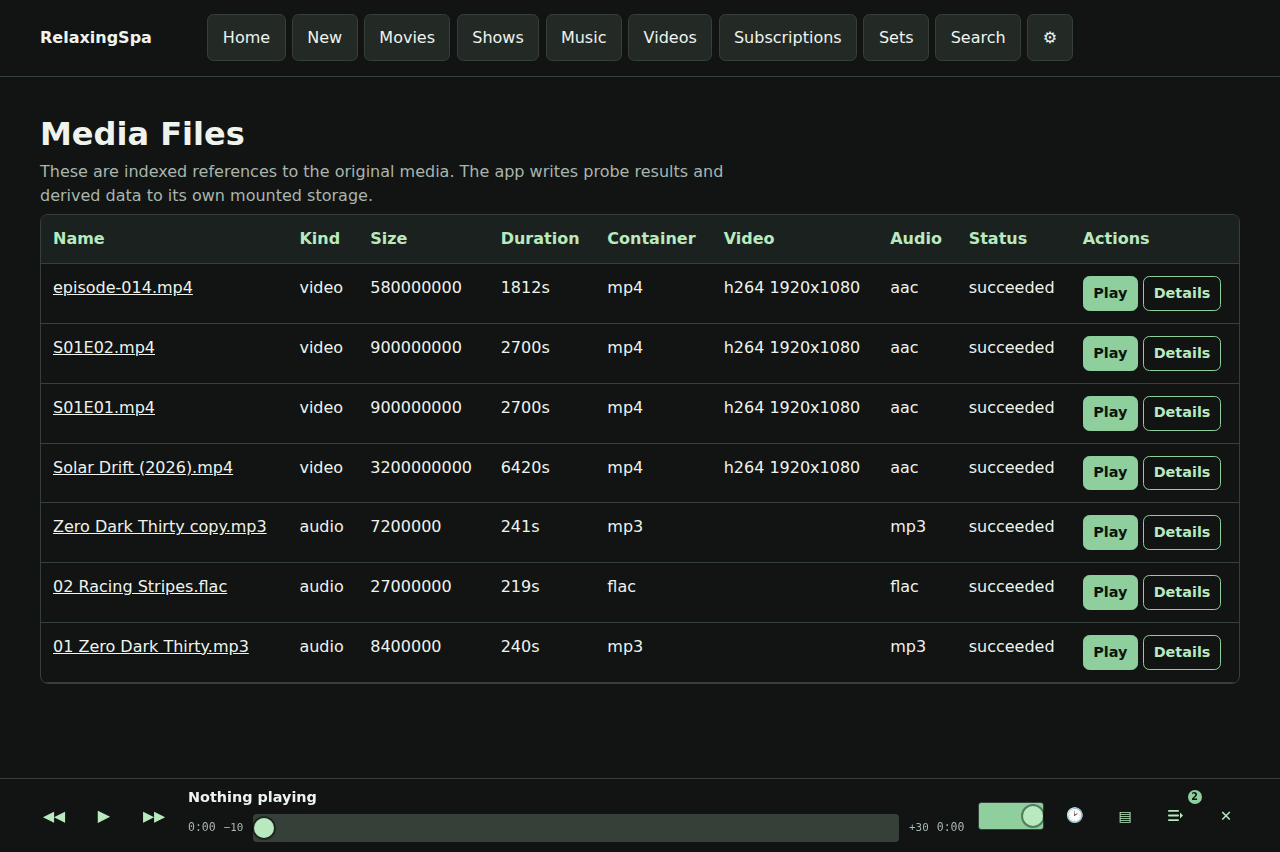
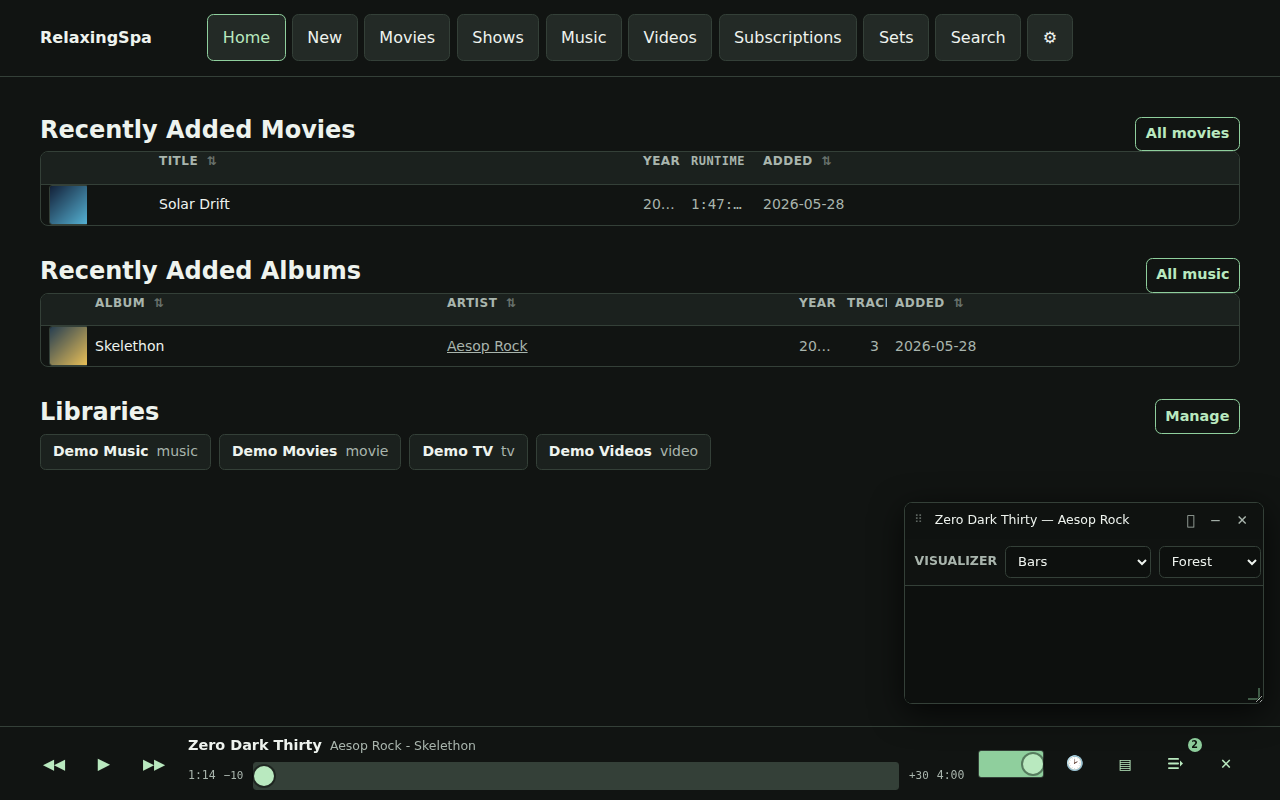

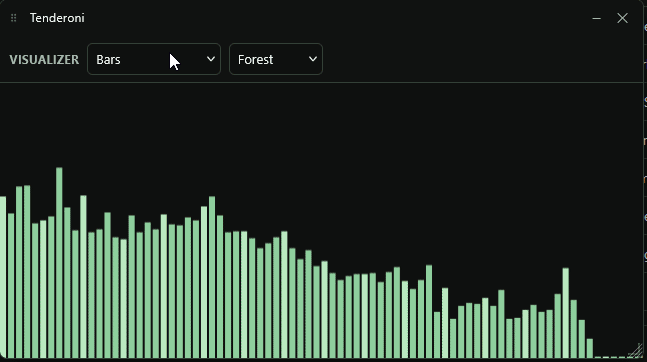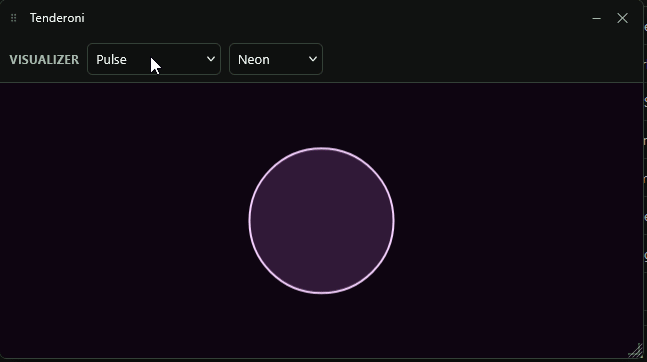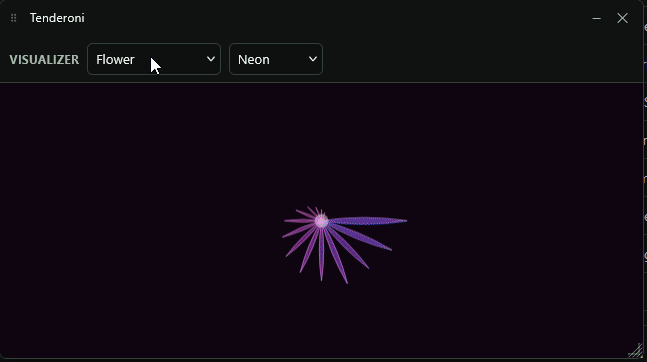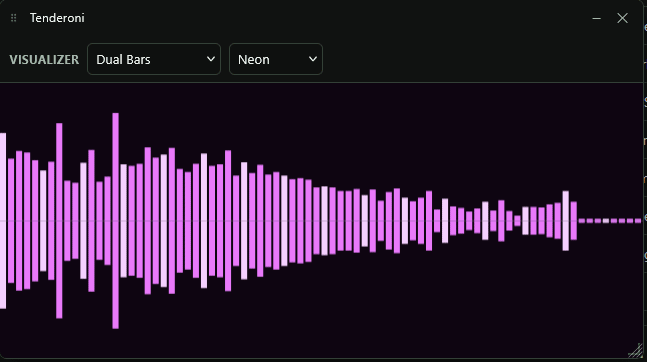
There’s also some easter eggs, for instance – here’s a gif of the visualizers available.
When I started this project I was playing with python, but the speed and the delivery mechanism wasn’t the play. I quickly switched to Go because of its extremely simple deployment story, while the language is one I am pretty unfamiliar with, I really like the results! Maybe I should build in Go more.
For now, I am not releasing this code online – the tool serves me, but if you want a copy hit me up via email at my first name at this domain and let’s chat!