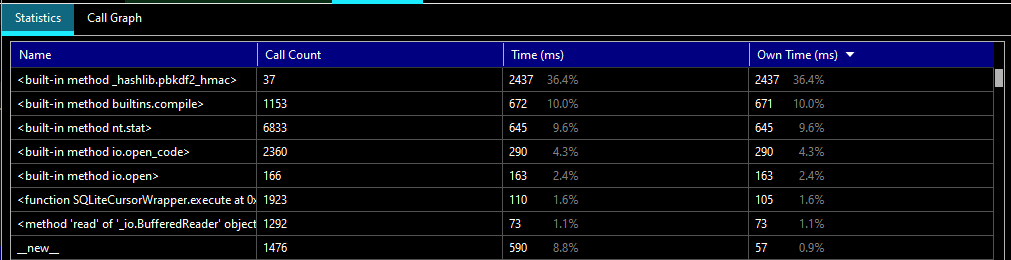
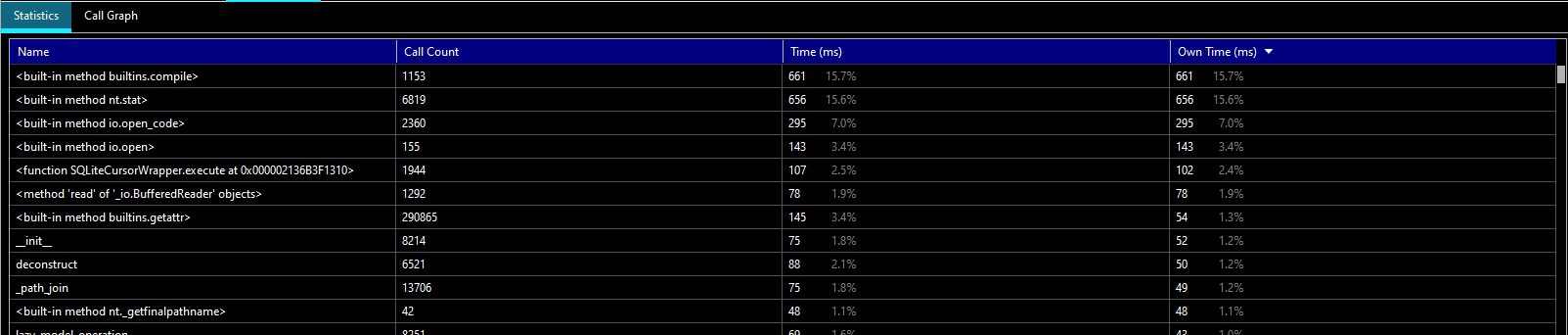
Poetry bills itself as “Python packaging and dependency management made easy” – I will dive in a bit more…
Installing and configuring
- Poetry requires Python 3.8+ (that’s a lot of missing Python)
- Has the classic “fun” insecure installer approach by default curl -sSL https://install.python-poetry.org | python3 – not my favorite, but it looks like Poetry has its own bootstrapping problem right now.
- Uses the pyproject.toml format for configuration, with the tool.poetry, tool.poetry.dependencies, and build-system are the most important starting fields.
- Poetry has a pretty well-thought-out use of the pyproject format.
Commands and Usage
- Initializing an existing project is as easy as poetry init it will ask you questions about your package and get your boostrapped.
- You can add packages with poetry add and poetry remove, first blush it feels like I am using cargo.
- Upon upgrade/change Poetry removes old packages.There are a few GitHub issues about it, so if you are Windows and you want a faultless experience you might want to skip Poetry for now.
- This will also resolve the package versions to ensure compatibility – a clear positive knowing your packages work out of the box together, but I have burned by Conda before, so a package solver always gets some side-eye.
- poetry install grabs the packages and installs them in your environment.
- poetry update Gets the latest versions of the dependencies and write them to your lock file.
- poetry run runs the command within the current virtualenv.
- This combines with the tool.poetry.scripts section of the pyproject file – you can define a file to run and then poetry run special-command to run your special-command.
- poetry shell spawns a shell in the virtual environment (really useful for testing random stuff).
- There’s a few more commands around lock files and more esoteric needs for the build system, so I will stop there for now.
Other interesting differences from a simplified pip env
- Poetry is much more active in managing environments than a simple pip+venv setup, and actively takes steps to activate/validate the version of Python and your current environment when running code.
- There’s a bit more on the type of build tools you can emit, versioning, and dependency groups which you generally wouldn’t have in the simpler tooling modes.
Final Thoughts
Overall my first blush with Poetry is that it’s a very cool tool (if you are not on Windows) and that it definitely seems that once it’s set up. It seems like you’d have more luck getting new packages added to existing projects without the “fun” of Python packaging issues arising suddenly in the wild (or hopefully your full featured test suite)/
Because of the file deletion issue (and me on Windows most of the time) I am still going to be sticking to pip+venv. Any add/remove command has about a 50% chance of going south for the boxes I am using.