Today I was diving into some extremely wide tables, I wanted to take a quick look at things like “How many unique values does this table have in every column?”.
This can be super useful if you have a spreadsheet of results or a schema without effective normalization and you want to determine which rows are the “most unique” – or have high cardinality.
The Github gist is embedded at the bottom of the page, but I will run you through the code in case you want an explanation of how it works
The procedure takes a schema and a table/view name and combines them – I could ask the user to do this for me, but there’s parts where its useful to break them up and I dont want to mess with split logic :p

The procedure is defined as a temporary stored procedure as I didnt want to leave a trace when I disconnect.
I then define the dynamic UNPIVOT statement, which we will feed our dynamic column listing from.

Gather our columns (twice) – once for the COUNT(DISTINCT), and once for the use in the columns we want to UNPIVOT.
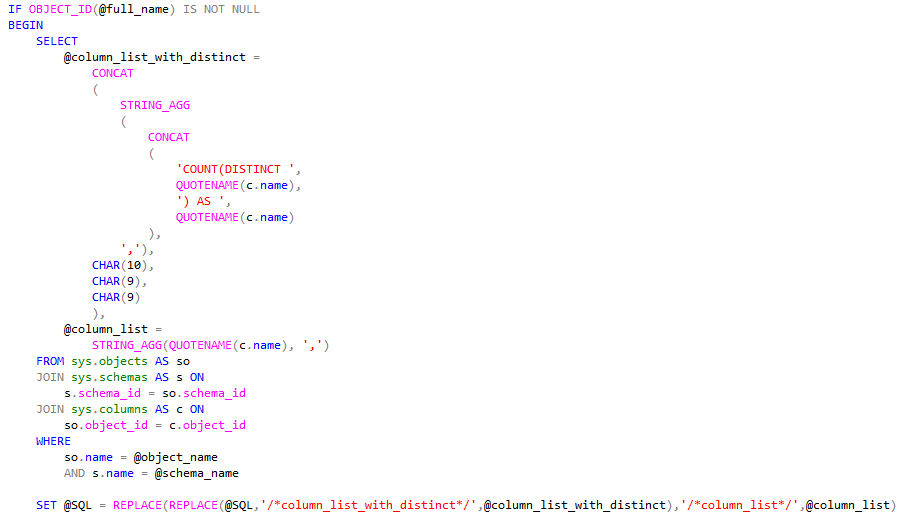
Here’s an example of running it against a tsqlt testresult table:
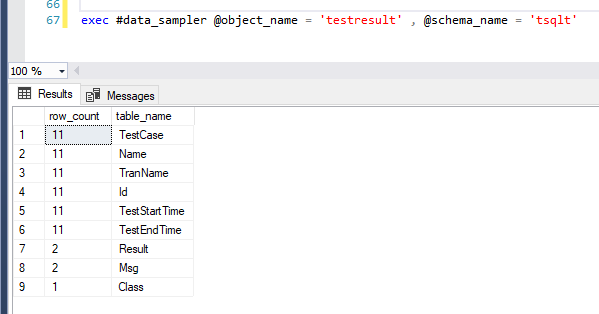
As we can see, the tsqlt testresult table has one class, two messages and results, and unique everything else (so that’s where I will focus.)
I also utilize a @magic_value variable in the code (not shown) which I use to deal with the fact that a NULL value in an UNPIVOT statement wont count as an occurrence. I want to disambiguate from NULL and any particular value that might occur, so using something like -1 or some string NULL would be inappropriate.
That’s it for today!
Grab the full code below –