Just a quick one in case I forget – I had a scenario where I needed to replace fn_varbintohexstr in converting an existing product to something more Azure SQL DB friendly.
I did some googling and didn’t like the results, especially since most of them are returning NVARCHAR(MAX) instead of what they generally should – just VARCHAR(length of data) and in the case of my needs (timestamps) the value was always 18 characters.
The key was finding the conversion to binary first, and then the use of the ,1 param for convert.
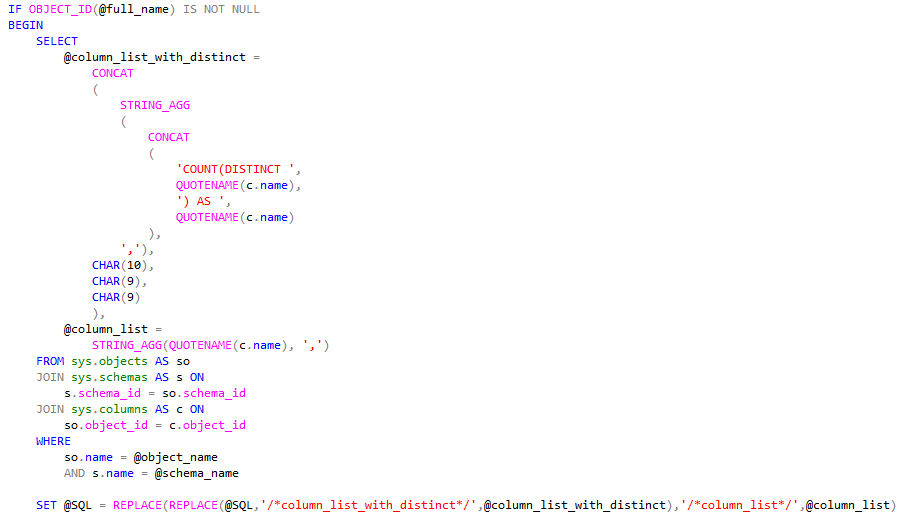
Today I was diving into some extremely wide tables, I wanted to take a quick look at things like “How many unique values does this table have in every column?”.
This can be super useful if you have a spreadsheet of results or a schema without effective normalization and you want to determine which rows are the “most unique” – or have high cardinality.
The Github gist is embedded at the bottom of the page, but I will run you through the code in case you want an explanation of how it works
The procedure takes a schema and a table/view name and combines them – I could ask the user to do this for me, but there’s parts where its useful to break them up and I dont want to mess with split logic :p
The procedure is defined as a temporary stored procedure as I didnt want to leave a trace when I disconnect.
I then define the dynamic UNPIVOT statement, which we will feed our dynamic column listing from.
Gather our columns (twice) – once for the COUNT(DISTINCT), and once for the use in the columns we want to UNPIVOT.
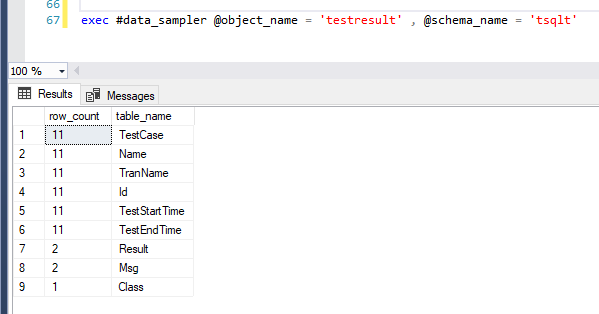
Here’s an example of running it against a tsqlt testresult table:
As we can see, the tsqlt testresult table has one class, two messages and results, and unique everything else (so that’s where I will focus.)
I also utilize a @magic_value variable in the code (not shown) which I use to deal with the fact that a NULL value in an UNPIVOT statement wont count as an occurrence. I want to disambiguate from NULL and any particular value that might occur, so using something like -1 or some string NULL would be inappropriate.
Update: This blog post is already out of date due to the hard work of the ADS team! Check my Azure Data Studio Notebook Update for more details of why you can skip my warnings about your internet connection.
I have been waiting for word about the new Notebook functionality in Azure Data Studio, and when I heard it was available in the insider build, I jumped in to take a look.
A Jupyter Notebook is a web application that allows you to host programming languages, run code (often with different programming languages), return results, annotate your data, and importantly, share the source controlled results with your colleagues.
Alright, here’s what I did:
Grab the insider’s build from Github.
Install Azure Data Studio (ADS.)
Create a new Notebook (and have it download some stuff.)
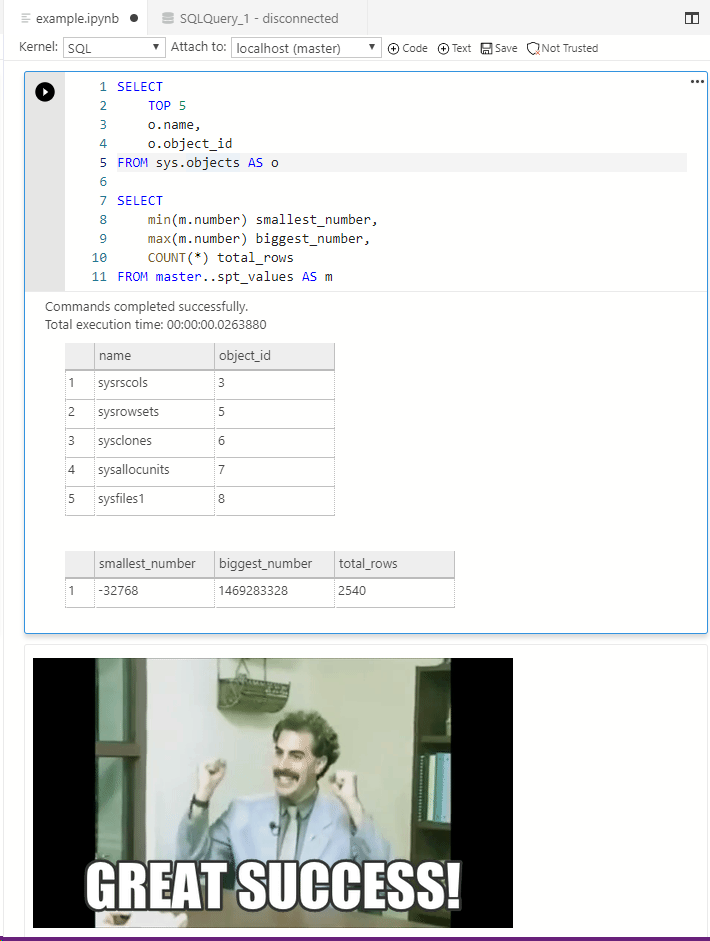
Run some queries!
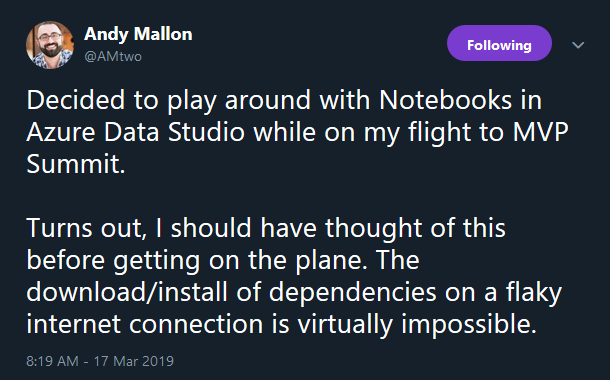
Keep in mind I am talking about the Insider’s Build as of as of Thursday March 7, 2019 – if you download it in the future changes are likely to have occurred.
If you want to follow along, make SURE you have a solid internet connection available, planes do NOT count.
Keep in mind you may want to disable updates when running the insider version, as it will try to update to the stable channel version. Thanks to Shawn Melton for the tip!
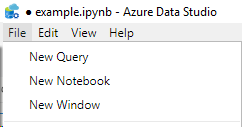
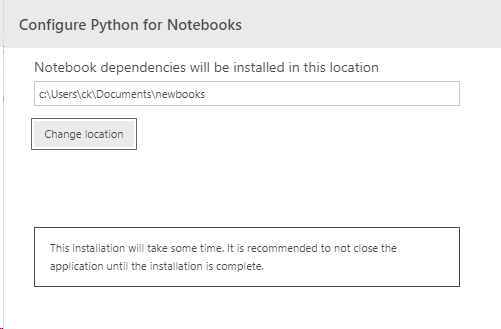
Install the tools by choosing File -> New Notebook.
The install process will warn you this will take awhile to download and configure the Jupyter environment (which includes python and a few other dependencies.)
Every time you create a new notebook, you are going to download the required dependencies from scratch – this is to ensure you have an isolated environment per notebook, but its worth keeping in mind for now.
Go get some coffee, its going to be a bit.
Maybe time for that second cup.
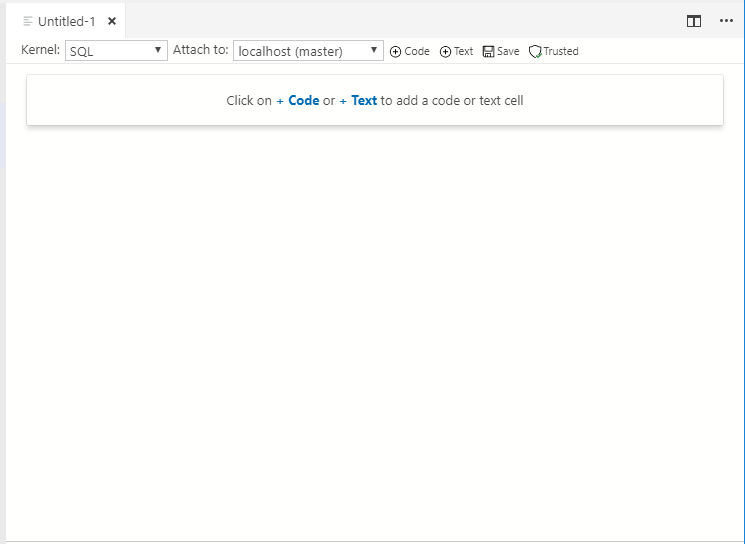
When our new notebook pops up, you should immediately be offered an option for a Code(TSQL) or a Text(markdown) box.
All the data you return is saved into your notebook, so you can see the same results as I did if you download my notebook, and you can replay it in your environment to see if it is the same.
Going to end it there for now, but I am excited to see what people will begin passing around in notebooks for debugging, training, and demonstration purposes!
Some issues I am going to be keeping my eyeballs on the next few weeks: