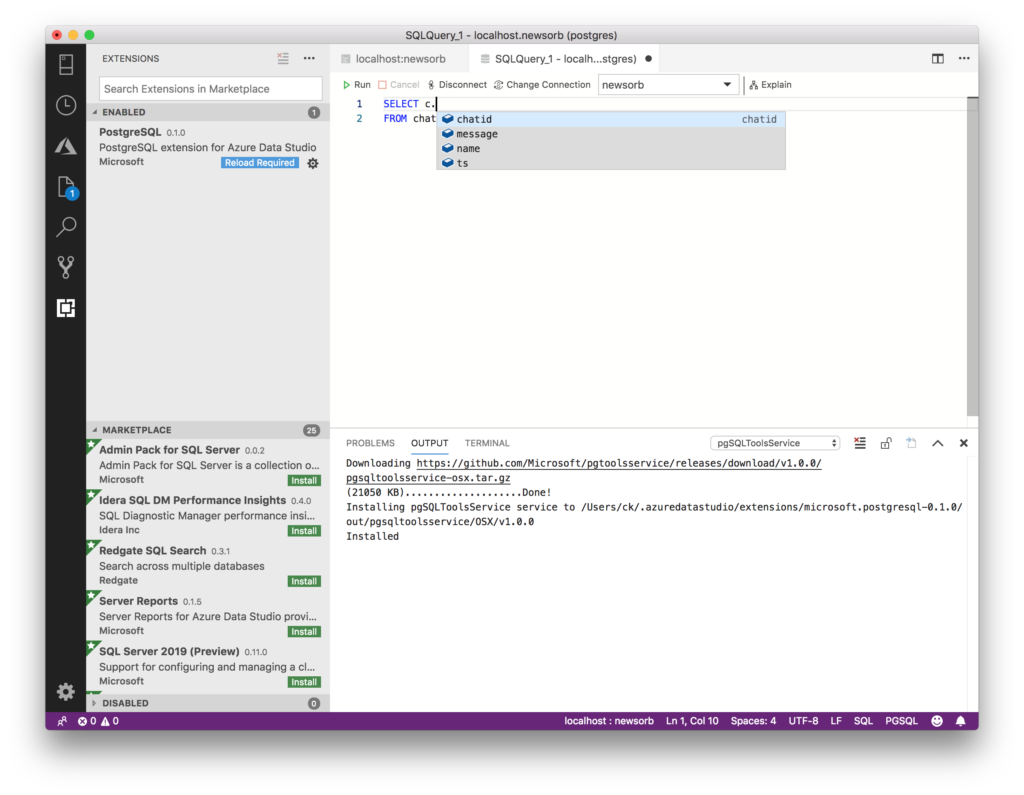
Today Thomas Rayner’s post on Get-History reminded me of a one liner I use to calculate time spent on the last command.
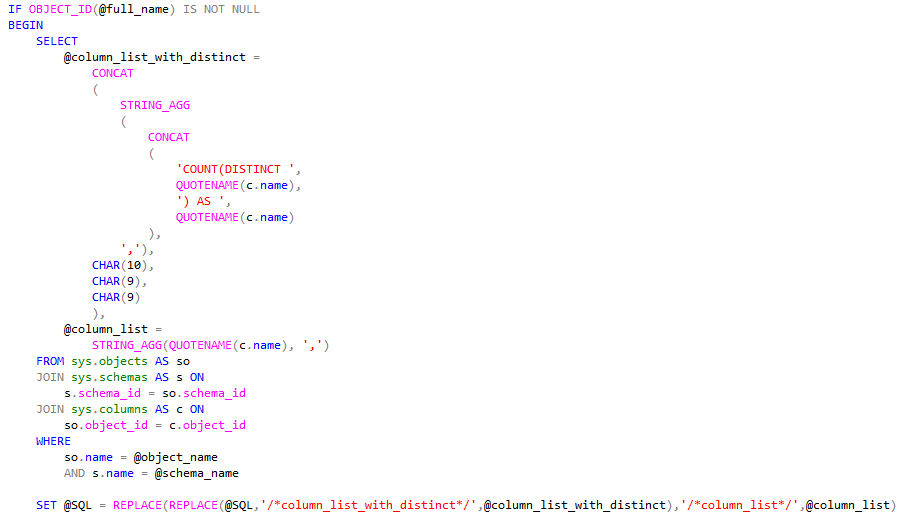
(Get-History)[-1].EndExecutionTime - (Get-History)[-1].StartExecutionTime
Days : 0
Hours : 0
Minutes : 0
Seconds : 0
Milliseconds : 87
Ticks : 870022
TotalDays : 1.00696990740741E-06
TotalHours : 2.41672777777778E-05
TotalMinutes : 0.00145003666666667
TotalSeconds : 0.0870022
TotalMilliseconds : 87.0022
You can select any property from the output and get just the TotalSeconds, but I like this simple output for when I have to leave some work in progress and I need to come back and check some time in the future.
If you are confused by this code and want further explanations, keep reading!
A typical Get-History call returns the following to Get-Member.
PS C:\temp> Get-History | Get-Member
TypeName: Microsoft.PowerShell.Commands.HistoryInfo
Name MemberType Definition
---- ---------- ----------
Clone Method Microsoft.PowerShell.Commands.HistoryInfo Clone()
Equals Method bool Equals(System.Object obj)
GetHashCode Method int GetHashCode()
GetType Method type GetType()
ToString Method string ToString()
CommandLine Property string CommandLine {get;}
EndExecutionTime Property datetime EndExecutionTime {get;}
ExecutionStatus Property System.Management.Automation.Runspaces.PipelineState ExecutionStatus {get;}
Id Property long Id {get;}
StartExecutionTime Property datetime StartExecutionTime {get;}
Ignoring the methods (as they are common) we see we have access to some useful properties:
- The CommandLine which contains the text typed in the console.
- The ExecutionStatus which tells you if your command was successful.
- The StartExecutionTime and EndExecutionTime, which store the start time and end time of your running command.
- The Id, which is just a sequential integer indicating its order in the history.
As is common in PowerShell, even though we see the list of members and properties the information actually only represents one item in the list of objects the command returns, one for each history row.
If you want to see an example this, we can use PowerShell’s comma/unary operator to roll our multiple elements into one bag of elements.
PS C:\temp> $many = Get-History # Assign all our Get-History rows to $many
PS C:\temp> $one = , (Get-History) # Prevent unrolling the items with the ,
PS C:\temp> $many.Count # I ran 18 previous commands when this was assigned
18
PS C:\temp> $one.count # This is a bag holding 18 items
1
This technique was new to me when I first started PowerShell, but a useful trick if you want to write a function that returns an object representing the entire list, instead of returning a series of elements. If you want to learn more about the Comma operator, check the documentation in about_Operators.
The next step is to ask for the first element of a list, which PowerShell supports with bracket notation (list)[element_number], with 0 being the first number (as all sane programming languages choose.)
We use dot notation to access the properties of EndExecutionTime and StartExecutionTime, once each for our specific list item, (list)[element_number].property.
Lastly, we subtract the properties from one another (list)[element_number].property – (list)[element_number].property, which PowerShell determines behind the scenes is two dates being subtracted, performs the required math, and usefully returns a useful System.TimeSpan type representing the time between the two dates.
Special thanks to Contributing Editor John G Hohengarten for his thoughtful additions to this post.